内存对齐
什么是内存对齐
弄明白什么是内存对齐的时候,先来看一个demo
type s struct {
Bool bool
Byte byte
In32 int32
Int64 int64
Int8 int8
}
func main() {
fmt.Printf("bool size: %d\n", unsafe.Sizeof(bool(true)))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(int32(0)))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(int8(0)))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(int64(0)))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(byte(0)))
fmt.Printf("string size: %d\n", unsafe.Sizeof("E"))
part1 := s{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
}
打印下输出
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1
string size: 16
part1 size: 24, align: 8
按照不能类型的长度计算,结构体s的长度应该是1+1+4+8+1=15,但是我们通过unsafe.Sizeof()计算出来的长度是24。这就是发生了内存对齐造成的。
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问, 这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是内存对齐。
为什么需要内存对齐
1、平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
减少次数
我们认为的内存空间可能是简单的字节数组

但是处理器对待内存不是这样的,CPU把内存当作一块一块的,块的大小可以是2、4、8、16字节大小,因此CPU读取内存是一块一块读取的。(块的大小称为内存读取粒度)

如果没有内存对齐:
假设当前内存读取粒度为4
假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的连续四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器.这需要做很多工作。
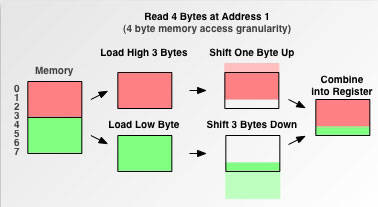
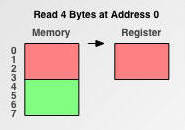
如果内存对齐了:
现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
保障原子性
如果地址未对齐,则至少需要两次内存访问。但是,如果所需数据跨越虚拟内存的两页会发生什么?这可能导致驻留第一页而没有驻留最后一页的情况。访问时,在指令中间,将产生页面错误,执行虚拟内存管理交换代码,从而破坏指令的原子性。
合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
对齐系数
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令#pragma pack(n)进行变更,n就是代指 “对齐系数”。
一般来讲,我们常用的平台的系数如下:
-
32 位:4
-
64 位:8
查看几种类型的对齐系数
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("test"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
对齐系数
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
不同的平台对齐系数可能不同,根据电脑的实际情况做分析
对齐规则
1、对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的起始位置必须是默认对齐长度和该数据成员长度中最小的长度的倍数。
2、除了结构成员需要对齐,结构本身也需要对齐,结构的长度必须是编译器默认的对齐长度和成员中最长类型中最小的数据大小的倍数对齐。
我们根据上面的例子具体的分析下
type s struct {
Bool bool
Byte byte
In32 int32
Int64 int64
Int8 int8
}
对齐流程
- 第一个成员
Bool- 类型: bool
- 大小/对齐值: 1
- 占用地址空间: 1
- 结构内存起始偏移量: 0
- 对齐Padding空间:0
- 对齐当前偏移量: 1
- 第二个成员
Byte- 类型: byte
- 大小/对齐值: 1
- 占用地址空间: 1
- 结构内存起始偏移量: 1
- 对齐Padding空间:0 根据规则1,当前成员
大小/对齐值1,所以不用padding - 对齐当前偏移量: 2
- 第三个成员
In32- 类型: int32
- 大小/对齐值: 4
- 占用地址空间: 4
- 结构内存起始偏移量: 2
- 对齐Padding空间:2 根据规则1,当前成员
大小/对齐值4,但是结构内存起始偏移量是2,2不是4的最小倍数,所以要padding空间为2 - 对齐当前偏移量: 8
- 第四个成员
Int64- 类型: int64
- 大小/对齐值: 8
- 占用地址空间: 8
- 结构内存起始偏移量: 8
- 对齐Padding空间:0 根据规则1,当前成员
大小/对齐值8,当前结构内存起始偏移量是8,所以不用padding - 对齐当前偏移量: 16
- 第五个成员
Int8- 类型: nt8
- 大小/对齐值: 4
- 占用地址空间: 4
- 结构内存起始偏移量: 16
- 对齐Padding空间:0 根据规则1,当前成员
大小/对齐值4,当前结构内存起始偏移量是16,所以不用padding - 对齐当前偏移量: 20
- 结束
- 起始地址: 20
- 对齐Padding空间:4 根据规则2,当前成员中最长类型中最小的数据大小为8,当前结构内存起始偏移量是20,所以要padding空间为4
- 对齐当前偏移量: 24
内存对齐主要的依据就是上面两个对齐的规则,数据成员的起始位置必须是默认对齐长度和该数据成员长度中最小的长度的倍数,同时对于整个结构对象,最终的地址要是编译器默认的对齐长度和成员中最长类型中最小的数据大小的倍数。
总结
1、内存对齐是不可缺少的,能够减少cpu的访问内存的次数;
2、合理的内存布局也便于实现变量操作的原子性;
3、不同硬件平台占用的大小和对齐值都可能是不一样的。
参考
【在 Go 中恰到好处的内存对齐】https://eddycjy.gitbook.io/golang/di-1-ke-za-tan/go-memory-align
【golang 内存对齐】https://xie.infoq.cn/article/594a7f54c639accb53796cfc7
【C/C++内存对齐详解】https://zhuanlan.zhihu.com/p/30007037
【内存对齐详解】https://developer.aliyun.com/article/32177
【go内存对齐】https://www.kancloud.cn/golang_programe/golang/1144263
【Go struct 内存对齐】https://geektutu.com/post/hpg-struct-alignment.html
【Memory access granularity】https://developer.ibm.com/articles/pa-dalign/?mhsrc=ibmsearch_a&mhq=Straighten%20up%20and%20fly%20right
【为什么要内存对齐 Data alignment: Straighten up and fly right】https://blog.csdn.net/lgouc/article/details/8235471