RabbitMQ 如何做分布式
前言
前面几篇文章介绍了消息队列中遇到的问题,这篇来聊聊 RabbitMQ 的集群搭建。
集群配置方案
RabbitMQ 中集群的部署方案有三种 cluster,federation,shovel。
cluster
cluster 有两种模式,分别是普通模式和镜像模式
cluster 的特点:
1、不支持跨网段,用于同一个网段内的局域网;
2、可以随意的动态增加或者减少;
3、节点之间需要运行相同版本的 RabbitMQ 和 Erlang 。
普通模式
cluster 普通模式(默认的集群模式),所有节点中的元数据是一致的,RabbitMQ 中的元数据会被复制到每一个节点上。
队列里面的数据只会存在创建它的节点上,其他节点除了存储元数据,还存储了指向 Queue 的主节点(owner node)的指针。
集群中节点之间没有主从节点之分。

举个栗子来说明下普通模式的消息传输:
假设我们 RabbitMQ 中有是三个节点,分别是 node1,node2,node3。如果队列 queue1 的连接创建发生在 node1 中,那么该队列的元数据会被同步到所有的节点中,但是 queue1 中的消息,只会在 node1 中。
- 如果一个消费者通过 node2 连接,然后来消费 queue1 中的消息?
RabbitMQ 会临时在 node1、node2 间进行消息传输,因为非 owner 节点除了存储元数据,还会存储指向 Queue 的主节点(owner node)的指针。RabbitMQ 会根据这个指向,把 node1 中的消息实体取出并经过 node2 发送给 consumer 。
- 如果一个生产者通过 node2 连接,然后来向 queue1 中生产数据?
同理,RabbitMQ 会根据 node2 中的主节点(owner node)的指针,把消息转发送给 owner 节点 node1,最后插入的数据还是在 node1 中。
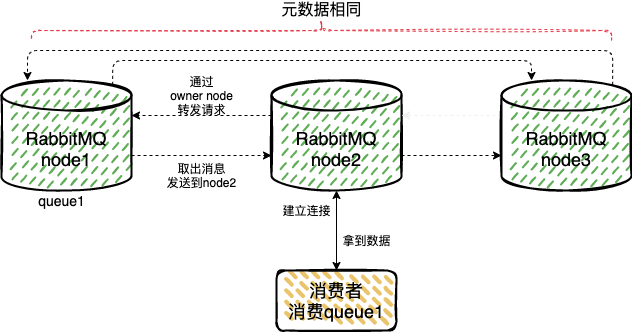
同时对于队列的创建,要平均的落在每个节点上,如果只在一个节点上创建队列,所有的消费,最终都会落到这个节点上,会产生瓶颈。
存在的问题:
如果 node1 节点故障了,那么 node2 节点无法取出 node1 中还未消费的消息实体。
1、如果做了队列的持久化,消息不会被丢失,等到 node1 恢复了,就能接着进行消费,但是在恢复之前其他节点不能创建 node1 中已将创建的队列。
2、如果没有做持久化,消息会丢失,但是 node1 中的队列,可以在其他节点重新创建,不用等待 node1 的恢复。
普通模式不支持消息在每个节点上的复制,当然 RabbitMQ 中也提供了支持复制的模式,就是镜像模式(参见下文)。
镜像模式
镜像队列会在节点中同步队列的数据,最终的队列数据会存在于每个节点中,而不像普通模式中只会存在于创建它的节点中。
优点很明显,当有主机宕机的时候,因为队列数据会同步到所有节点上,避免了普通模式中的单点故障。
缺点就是性能不好,集群内部的同步通讯会占用大量的网络带宽,适合一些可靠性要求比较高的场景。
针对镜像模式 RabbitMQ 也提供了几种模式,有效值为 all,exactly,nodes 默认为 all。
-
all 表示集群中所有的节点进行镜像;
-
exactly 表示指定个数的节点上进行镜像,节点个数由
ha-params指定; -
nodes 表示在指定的节点上进行镜像,节点名称由
ha-params指定;
所以针对普通队列和镜像队列,我们可以选择其中几个队列作为镜像队列,在性能和可靠性之间找到一个平衡。
关于镜像模式中消息的复制,这里也用的很巧妙,值得借鉴
1、master 节点向 slave 节点同步消息是通过组播 GM(Guaranteed Multicast) 来同步的。
2、所有的消息经过 master 节点,master 对消息进行处理,同时也会通过 GM 广播给所有的 slave,slave收到消息之后在进行数据的同步操作。
3、GM 实现的是一种可靠的组播通信协议,该协议能保证组播消息的原子性。具体如何实现呢?
它的实现大致为:将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上 当有节点失效时,相邻的节点会接管以保证本次广播的消息会复制到所有的节点。
因为是一个循环链表,所以 master 发出去的消息最后也会返回到 master 中,master 如果收到了自己发出的操作命令,这时候就可以确定命令已经同步到了所有的节点。

federation
federation 插件的设计目标是使 RabbitMQ 在不同的 Broker 节点之间进行消息传递而无需建立集群。
看了定义还是很迷糊,来举举栗子吧
假设我们有一个 RabbitMQ 的集群,分别部署在不同的城市,那么我们假定分别是在北京,上海,广州。
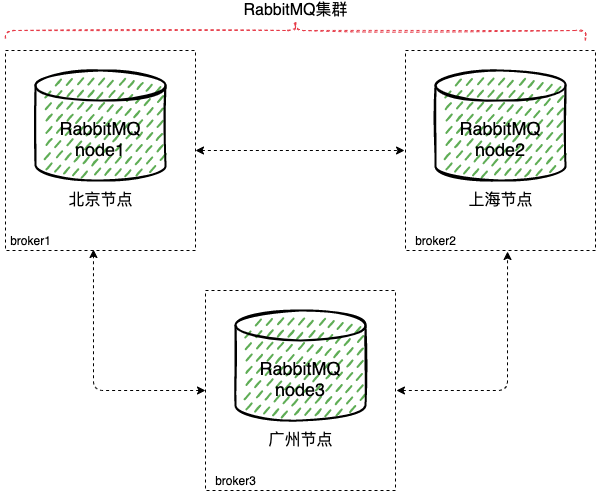
如果一个现在有一个业务 clientA,部署的机器在北京,然后连接到北京节点的 broker1 。然后网络连通性也很好,发送消息到 broker1 中的 exchangeA 中,消息能够很快的发送到,就算在开启了 publisher confirm 机制或者事务机制的情况下,也能快速确认信息,这种情况下是没有问题的。
如果一个现在有一个业务 clientB,部署的机器在上海,然后连接到北京节点的 broker1 。然后网络连通性不好,发送消息到 broker1 中的 exchangeA 中,因为网络不好,所以消息的确认有一定的延迟,这对于我们无疑使灾难,消息量大情况下,必然造成数据的阻塞,在开启了 publisher confirm 机制或者事务机制的情况下,这种情况将会更严重。
当然如果把 clientB ,部署在北京的机房中,这个问题就解决了,但是多地容灾就不能实现了。
针对这种情况如何解决呢,这时候 federation 就登场了。
比如位于上海的业务 clientB,连接北京节点的 broker1。然后发送消息到 broker1 中的 exchangeA 中。这时候是存在网络连通性的问题的。
-
1、让上海的业务 clientB,连接上海的节点 broker2;
-
2、通过 Federation ,在北京节点的 broker1 和上海节点的 broker2 之间建立一条单向的
Federation link; -
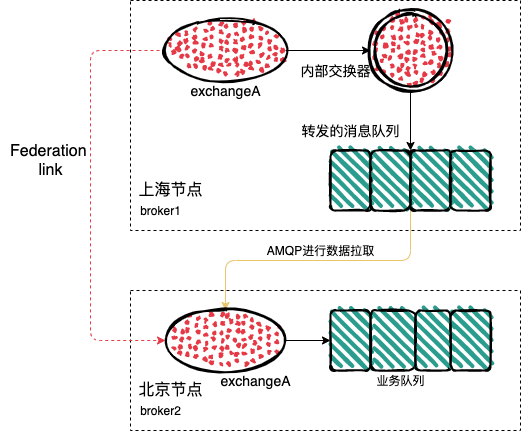
3、Federation 插件会在上海节点的 broker2 中创建一个同名的交换器 exchangeA (具体名字可配置,默认同名), 同时也会创建一个内部交换器,通过路由键 rkA ,将这两个交换器进行绑定,同时也会在 broker2 中创建一个
1、Federation 插件会在上海节点的 broker2 中创建一个同名的交换器 exchangeA (具体名字可配置,默认同名);
2、Federation 插件会在上海节点的 broker2 中创建一个内部交换器,通过路由键 rkA ,将 exchangeA 和内部交换器进行绑定;
3、Federation 插件会在上海节点的 broker2 中创建队列,和内部交换器进行绑定,同时这个队列会和北京节点的 broker1 中的 exchangeA,建立一条 AMQP 链接,来实时的消费队列中的消息了;
-
4、经过上面的流程,就相当于在上海节点 broker2 中的 exchangeA 和北京节点 broker1 中的 exchangeA 建立了
Federation link;
这样位于上海的业务 clientB 链接到上海的节点 broker2,然后发送消息到该节点中的 exchangeA,这个消息会通过Federation link,发送到北京节点 broker1 中的 exchangeA,所以可以减少网络连通性的问题。
shovel
连接方式与 federation 的连接方式类似,不过 shovel 工作更低一层。federation 是从一个交换器中转发消息到另一个交换器中,而 shovel 只是简单的从某个 broker 中的队列中消费数据,然后转发消息到另一个 broker 上的交换器中。
shovel 主要是:保证可靠连续地将 message 从某个 broker 上的 queue (作为源端)中取出,再将其 publish 到另外一个 broker 中的相应 exchange 上(作为目的端)。
作为源的 queue 和作为目的的 exchange 可以同时位于一个 broker 上,也可以位于不同 broker 上。Shovel 行为就像优秀的客户端应用程序能够负责连接源和目的地、负责消息的读写及负责连接失败问题的处理。
Shovel 的主要优势在于:
1、松藕合:Shovel 可以移动位于不同管理域中的 Broker (或者集群)上的消息,这些 Broker (或者集群〉可以包含不同的用户和 vhost ,也可以使用不同的 RabbitMQ 和 Erlang 版本;
2、支持广域网:Shovel 插件同样基于 AMQP 协议 Broker 之间进行通信 被设计成可以容忍时断时续的连通情形 井且能够保证消息的可靠性;
3、高度定制:当 Shove 成功连接后,可以对其进行配置以执行相关的 AMQP 命令。
使用 Shove 解决消息堆积
对于消息堆积,如果消息堆积的数量巨大时,消息队列的性能将严重收到影响,通常的做法是增加消费者的数量或者优化消费者来处理
如果一些消息堆积场景不能简单的增加消费者的数量来解决,就只能优化消费者的消费能力了,但是优化毕竟需要时间,这时候可以通过 Shove 解决
可以通过 Shove 将阻塞的消息,移交给另一个备份队列,等到本队列的消息没有阻塞了,然后将备份队列中的消息重新’铲’过来

节点类型
RAM node
内存节点将所有的队列、交换机、绑定、用户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
Disk node
元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启RabbitMQ的时候,丢失系统的配置信息
RabbitMQ要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。
如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。针对这种情况可以设置两个磁盘节点、至少保证一个是可用的,就能保证元数据的修改了。
看了很多文章,有的地方会认为所有持久化的消息都会存储到磁盘节点中,这是不正确的。对于内存节点,如果消息进行了持久化的操作,持久化的消息会存储在该节点中的磁盘中,而不是磁盘节点的磁盘中。
来个栗子:
这里构建了一个普通的 cluster 集群(见下文),选择其中的一个内存节点,推送消息到该节点中,并且每条消息都选择持久化,来看下,这个节点的内存变化
来看下没有消息时,节点中的内存占用
![]()
这里向rabbitmqcluster1推送了 397330 条消息,发现磁盘内存从原来的 6.1GiB 变成了 3.9GiB,而磁盘节点的内存没有变化
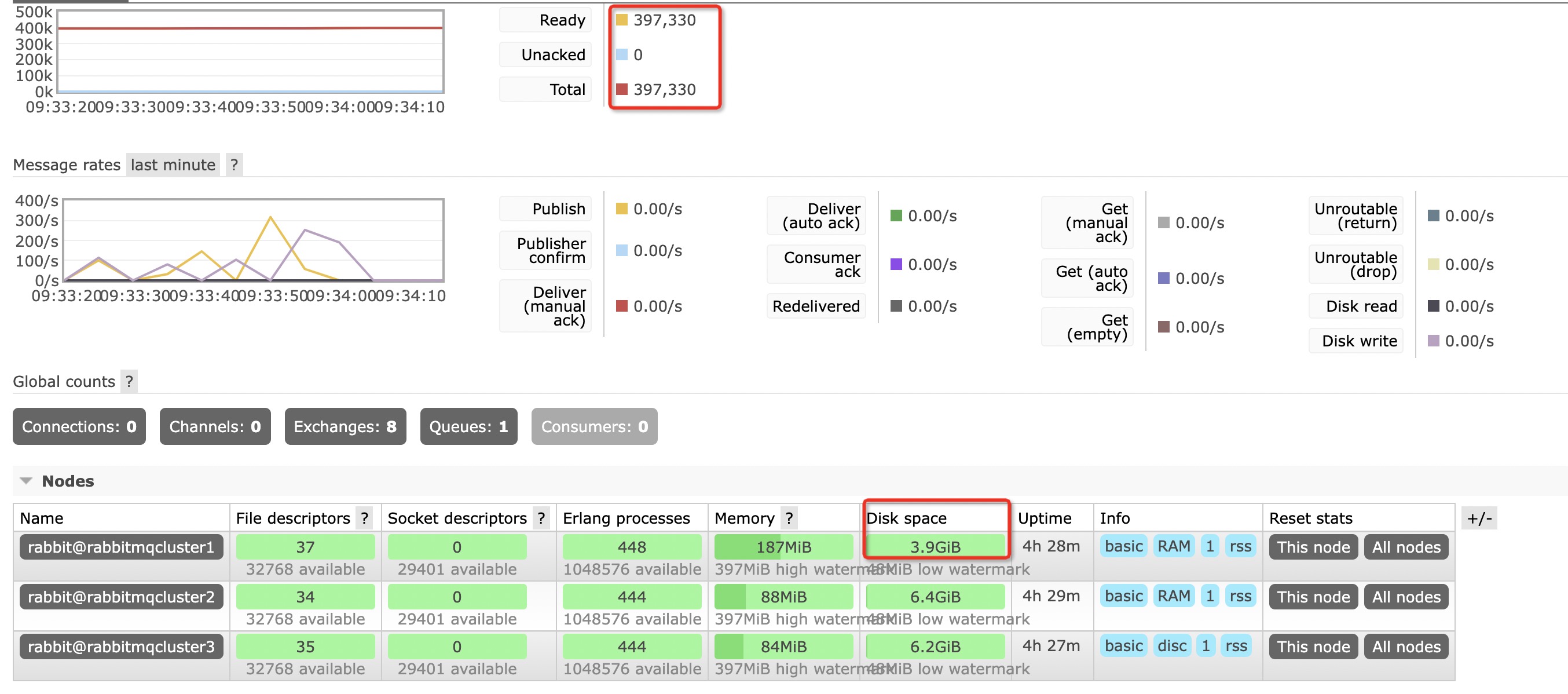
对于内存节点,如果消息进行了持久化的操作,持久化的消息会存储在该节点中的磁盘中,而不是磁盘节点的磁盘中。
集群的搭建
这是搭建一个普通的 cluster 模式,使用 vagrant 构建三台 centos7 虚拟机,vagrant构建centos虚拟环境
1、局域网配置
首先配置 hostname
$ hostnamectl set-hostname rabbitmqcluster1 --static
重启即可查看最新的 hostname
$ hostnamectl
Static hostname: rabbitmqcluster1
Icon name: computer-vm
Chassis: vm
Machine ID: e147b422673549a3b4fda77127bd4bcd
Boot ID: aa195e0427d74d079ea39f344719f59b
Virtualization: oracle
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-327.4.5.el7.x86_64
Architecture: x86-64
然后在三个节点的/etc/hosts下设置相同的配置信息
192.168.56.111 rabbitmqcluster1
192.168.56.112 rabbitmqcluster2
192.168.56.113 rabbitmqcluster3
2、每台及其中安装 RabbitMQ
具体的安装过程可参见Centos7安装RabbitMQ最新版3.8.5,史上最简单实用安装步骤
3、设置不同节点间同一认证的Erlang Cookie
每台机器中安装 RabbitMQ ,都会生成单独的Erlang Cookie。Erlang Cookie是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的Erlang Cookie。具体的目录存放在/var/lib/rabbitmq/.erlang.cookie。
所以这里把 rabbitmqcluster1 中的Erlang Cookie,复制到其他机器中,覆盖原来的Erlang Cookie。
$ scp /var/lib/rabbitmq/.erlang.cookie 192.168.56.112:/var/lib/rabbitmq
$ scp /var/lib/rabbitmq/.erlang.cookie 192.168.56.113:/var/lib/rabbitmq
复制Erlang Cookie之后重启 rabbitmq
$ systemctl restart rabbitmq-server
4、使用 -detached运行各节点
rabbitmqctl stop
rabbitmq-server -detached
5、将节点加入到集群中
在 rabbitmqcluster2 和 rabbitmqcluster3 中执行
$ rabbitmqctl stop_app
$ rabbitmqctl join_cluster rabbit@rabbitmqcluster1
$ rabbitmqctl start_app
默认 rabbitmq 启动后是磁盘节点,所以可以看到集群启动之后,节点类型都是磁盘类型

一般添加1到2个磁盘节点,别的节点节点为内存节点,这里我们将 rabbitmqcluster3 设置成磁盘节点,其他节点设置成内存节点
修改 rabbitmqcluster1 和 rabbitmqcluster2 节点类型为内存节点
$ rabbitmqctl stop_app
$ rabbitmqctl change_cluster_node_type ram
$ rabbitmqctl start_app

6、查看集群状态
$ rabbitmqctl cluster_status
参考
【RabbitMQ分布式集群架构和高可用性(HA)】http://chyufly.github.io/blog/2016/04/10/rabbitmq-cluster/
【RabbitMQ分布式部署方案简介】https://www.jianshu.com/p/c7a1a63b745d
【RabbitMQ实战指南】https://book.douban.com/subject/27591386/
【RabbitMQ两种集群模式配置管理】https://blog.csdn.net/fgf00/article/details/79558498