使用 String 类型内存开销大
如果我们有大量的数据需要来保存,在选型数据类型我们就需要知道 String 的内存开销是很大的
这里我们来分析下使用一个 String 类型需要用到的内存
1、简单动态字符串
Redis 中的 String,使用的是简单动态字符串(Simple Dynamic Strings,SDS)。
来看下数据结构
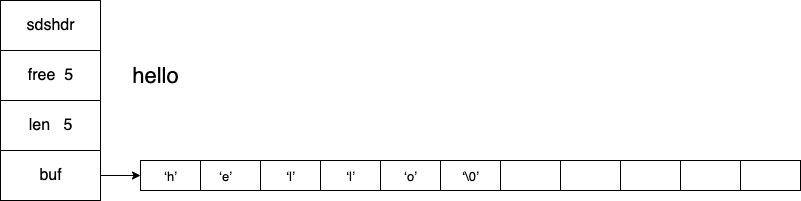
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 保存字符串的长度,不包含'\0'
long len;
// 记录buf数组中未使用字节的数量
long free;
// 字节数组,用于保存字符串
char buf[];
};
如果,使用 SDS 存储了一个字符串 hello,对应的 len 就是5,同时也申请了5个为未使用的空间,所以 free 就是5。对于 buf 来说,len 和 free 的内存占用都是额外开销。
2、RedisObject
因为 Redis 中有很多数据类型,对于这些不同的数据结构,Redis 为了能够统一处理,所以引入了 RedisObject。
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; // 编码
unsigned lru:LRU_BITS; // 最近被访问的时间
int refcount; // 引用次数
void *ptr; // 指向具体底层数据的指针
} robj;

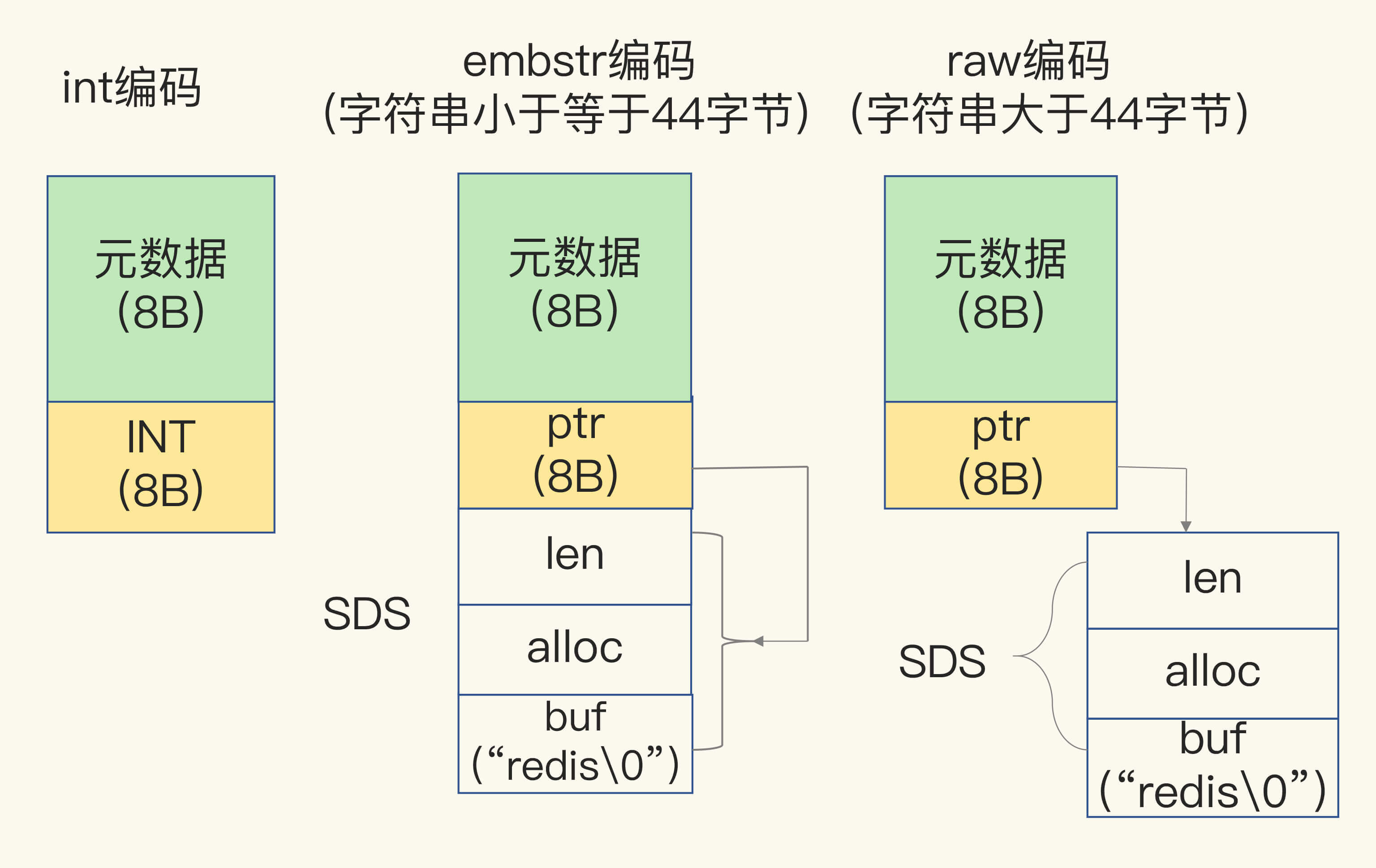
一个 RedisObject 包含了8字节的元数据和一个8字节指针,指针指向实际的数据内存地址。
不过需要注意的是这里 Redis 做了优化
1、当保存的数据是 Long 类型整数时,RedisObjec t中的指针就直接赋值为整数数据了,就不用使用额外的指针了。
2、如果保存的是字符串数据,并且字符串大小小于等于44字节时,RedisObject中的元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。
3、如果保存的是字符串数据,并且字符串大小大于44字节时,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。
这个引用一张Redis核心技术与实战中的图片
3、全局哈希表
Redis 中会有一个全局的哈希表来保存所有的键值对,哈希表中每一项存储的是 dictEntry 结构体
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
dictEntry 结构体中有三个指针,在64位机器下占24个字节,jemalloc 会为它分配32字节大小的内存单元。
jemalloc 作为 Redis 的默认内存分配器,在减小内存碎片方面做的相对比较好。jemalloc 在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当 Redis 存储数据时,会选择大小最合适的内存块进行存储。
所以选用 String 类型来存储字符串,上面的 RedisObject 结构、SDS 结构、dictEntry 结构的都会存在一定的内存开销
Redis 中的底层数据结构,提供了压缩列表,这种是很节省内存空间的。
我们可以使用 Hash 这种数据结构,因为在一定情况下这种结构底层的用的是压缩列表,这是一种很节省内存的数据结构。
使用 Hash 来存储
关于压缩列表的细节可参见Redis中的压缩列表

这些entry会挨个儿放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。
Redis基于压缩列表实现了 Hash 这样的集合类型,因为一个集合可以保存多个键值对,使用一个键值对就能对应到这个集合中了。使用 String 类型时,一个键值对就对应一个 dictEntry,这点对于使用集合类型来讲也是节省内存的一个点。
使用集合我们还需要注意一下几点:
1、我们要去保证存放到集合中的元素不要太多,使用 ziplist 作为内部数据结构的限制元素数默认不超过 512 个。可以通过修改配置来调整zset_max_ziplist_entries阀值的大小。如果超过了限制就不使用 ziplist 而是使用 Hash 类型来实现这个映射关系了。
2、同时元素也不能太少,如果一个 Hash 集合中只存入了一对filed/value,就相当于每个键值对也使用了一个全局的哈希表的 dictEntry。
3、同时键值对的 value 也不要太长,超过了hash-max-ziplist-value的限制也是会使用 Hash 类型而不是 ziplist。
原来使用 String 类型存储,是一个k/v结构,使用 Hash 类型,就需要两个 key 了,可以将原来的k/v中的 k 进行拆分,分成两部分即可。
127.0.0.1:6379> set 202220222111 xiaoming
OK
127.0.0.1:6379> hset 20222 0222111 xiaoming
(integer) 1
总结
String 类型的元数据是会占用一部分的内存空间,如果我们的数据,单个数据不大,但是数量很多,选用 String 这种类型的时候,需要考虑一下内存的占用。
参考
【Redis核心技术与实战】https://time.geekbang.org/column/intro/100056701
【Redis设计与实现】https://book.douban.com/subject/25900156/
【redis 一组kv实际内存占用计算】https://kernelmaker.github.io/Redis-StringMem
【Redis学习笔记】https://github.com/boilingfrog/Go-POINT/tree/master/redis