使用 Redis 实现消息队列
Redis 中也是可以实现消息队列
不过谈到消息队列,我们会经常遇到下面的几个问题
1、消息如何防止丢失;
2、消息的重复发送如何处理;
3、消息的顺序性问题;
关于 mq 中如何处理这几个问题,可参看RabbitMQ,RocketMQ,Kafka 事务性,消息丢失,消息顺序性和消息重复发送的处理策略
基于List的消息队列
对于 List
使用 LPUSH 写入数据,使用 RPOP 读出数据
127.0.0.1:6379> LPUSH test "ceshi-1"
(integer) 1
127.0.0.1:6379> RPOP test
"ceshi-1"
使用 RPOP 客户端就需要一直轮询,来监测是否有值可以读出,可以使用 BRPOP 可以进行阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。
127.0.0.1:6379> BRPOP test 10
后面的 10 是监听的时间,单位是秒,10秒没数据,就退出。
如果客户端从队列中拿到一条消息时,但是还没消费,客户端宕机了,这条消息就对应丢失了, Redis 中为了避免这种情况的出现,提供了 BRPOPLPUSH 命令,BRPOPLPUSH 会在消费一条消息的时候,同时把消息插入到另一个 List,这样如果消费者程序读了消息但没能正常处理,等它重启后,就可以从备份 List 中重新读取消息并进行处理了。
127.0.0.1:6379> LPUSH test "ceshi-1"
(integer) 1
127.0.0.1:6379> LPUSH test "ceshi-2"
(integer) 2
127.0.0.1:6379> BRPOPLPUSH test a-test 100
"ceshi-1"
127.0.0.1:6379> BRPOPLPUSH test a-test 100
"ceshi-2"
127.0.0.1:6379> BRPOPLPUSH test a-test 100
127.0.0.1:6379> RPOP a-test
"ceshi-1"
127.0.0.1:6379> RPOP a-test
"ceshi-2"
不过 List 类型并不支持消费组的实现,Redis 从 5.0 版本开始提供的 Streams 数据类型,来支持消息队列的场景。
分析下源码实现
在版本3.2之前,Redis中的列表是 ziplist 和 linkedlist 实现的,针对 ziplist 存在的问题, 在3.2之后,引入了 quicklist 来对 ziplist 进行优化。
对于 ziplist 来讲:
1、保存过大的元素,否则容易导致内存重新分配,甚至可能引发连锁更新的问题。
2、保存过多的元素,否则访问性能会降低。
quicklist 使多个数据项,不再用一个 ziplist 来存,而是分拆到多个 ziplist 中,每个 ziplist 用指针串起来,这样修改其中一个数据项,即便发生级联更新,也只会影响这一个 ziplist,其它 ziplist 不受影响。
下面看下 list 的实现
代码链接https://github.com/redis/redis/blob/6.2/src/t_list.c
void listTypePush(robj *subject, robj *value, int where) {
if (subject->encoding == OBJ_ENCODING_QUICKLIST) {
int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;
if (value->encoding == OBJ_ENCODING_INT) {
char buf[32];
ll2string(buf, 32, (long)value->ptr);
quicklistPush(subject->ptr, buf, strlen(buf), pos);
} else {
quicklistPush(subject->ptr, value->ptr, sdslen(value->ptr), pos);
}
} else {
serverPanic("Unknown list encoding");
}
}
/* Wrapper to allow argument-based switching between HEAD/TAIL pop */
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}
可以看下上面主要用到的是 quicklist
这里再来分析下 quicklist 的数据结构
typedef struct quicklist {
// quicklist的链表头
quicklistNode *head;
// quicklist的链表尾
quicklistNode *tail;
// 所有ziplist中的总元素个数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNodes的个数
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {
// 前一个quicklistNode
struct quicklistNode *prev;
// 后一个quicklistNode
struct quicklistNode *next;
// quicklistNode指向的ziplist
unsigned char *zl;
// ziplist的字节大小
unsigned int sz; /* ziplist size in bytes */
// ziplist中的元素个数
unsigned int count : 16; /* count of items in ziplist */
// 编码格式,原生字节数组或压缩存储
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
// 存储方式
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
// 数据是否被压缩
unsigned int recompress : 1; /* was this node previous compressed? */
// 数据能否被压缩
unsigned int attempted_compress : 1; /* node can't compress; too small */
// 预留的bit位
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
quicklist 作为一个链表结构,在它的数据结构中,是定义了整个 quicklist 的头、尾指针,这样一来,我们就可以通过 quicklist 的数据结构,来快速定位到 quicklist 的链表头和链表尾。

来看下 quicklist 是如何插入的
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
assert(sz < UINT32_MAX); /* TODO: add support for quicklist nodes that are sds encoded (not zipped) */
if (likely(
// 检测插入位置的 ziplist 是否能容纳该元素
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
// 容纳不了,就重新创建一个 quicklistNode
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
quicklist 采用的是链表结构,所以当插入一个新元素的时候,首先判断下 quicklist 插入位置的 ziplist 是否能容纳该元素,即单个 ziplist 是否不超过 8KB,或是单个 ziplist 里的元素个数是否满足要求。
如果可以插入就当前的节点进行插入,否则就新建一个 quicklistNode 来保存先插入的节点。
quicklist 通过控制每个 quicklistNode 中,ziplist 的大小或是元素个数,就有效减少了在 ziplist 中新增或修改元素后,发生连锁更新的情况,从而提供了更好的访问性能。
基于 Streams 的消息队列
Streams 是 Redis 专门为消息队列设计的数据类型。
-
是可持久化的,可以保证数据不丢失。
-
支持消息的多播、分组消费。
-
支持消息的有序性。
来看下几个主要的命令
XADD:插入消息,保证有序,可以自动生成全局唯一ID;
XREAD:用于读取消息,可以按ID读取数据;
XREADGROUP:按消费组形式读取消息;
XPENDING和XACK:XPENDING命令可以用来查询每个消费组内所有消费者已读取但尚未确认的消息,而XACK命令用于向消息队列确认消息处理已完成。
下面看几个常用的命令
XADD
使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列,XADD 语法格式:
$ XADD key ID field value [field value ...]
-
key:队列名称,如果不存在就创建
-
ID:消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性
-
field value:记录
$ XADD teststream * name xiaohong surname xiaobai
"1646650328883-0"
可以看到 1646650328883-0就是自动生成的全局唯一消息ID
XREAD
使用 XREAD 以阻塞或非阻塞方式获取消息列表
$ XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
-
count:数量
-
milliseconds:可选,阻塞毫秒数,没有设置就是非阻塞模式
-
key:队列名
-
id:消息 ID
$ XREAD BLOCK 100 STREAMS teststream 0
1) 1) "teststream"
2) 1) 1) "1646650328883-0"
2) 1) "name"
2) "xiaohong"
3) "surname"
4) "xiaobai"
BLOCK 就是阻塞的毫秒数
XGROUP
使用 XGROUP CREATE 创建消费者组
$ XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
-
key:队列名称,如果不存在就创建
-
groupname:组名
-
$:表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略
从头开始消费
$ XGROUP CREATE teststream test-consumer-group-name 0-0
从尾部开始消费
$ XGROUP CREATE teststream test-consumer-group-name $
XREADGROUP GROUP
使用 XREADGROUP GROUP 读取消费组中的消息
$ XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
-
group:消费组名
-
consumer:消费者名
-
count:读取数量
-
milliseconds:阻塞毫秒数
-
key:队列名
-
ID:消息 ID
$ XADD teststream * name xiaohong surname xiaobai
"1646653392799-0"
$ XREADGROUP GROUP test-consumer-group-name test-consumer-name COUNT 1 STREAMS teststream >
1) 1) "teststream"
2) 1) 1) "1646653392799-0"
2) 1) "name"
2) "xiaohong"
3) "surname"
4) "xiaobai"
消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了。
如果没有通过 XACK 命令告知消息已经成功消费了,该消息会一直存在,可以通过 XPENDING 命令查看已读取、但尚未确认处理完成的消息。
$ XPENDING teststream test-consumer-group-name
1) (integer) 3
2) "1646653325535-0"
3) "1646653392799-0"
4) 1) 1) "test-consumer-name"
2) "3"
分析下源码实现
stream 的结构
typedef struct stream {
// 这是使用前缀树存储数据
rax *rax; /* The radix tree holding the stream. */
uint64_t length; /* Number of elements inside this stream. */
// 当前stream的最后一个id
streamID last_id; /* Zero if there are yet no items. */
// 存储当前的消费者组信息
rax *cgroups; /* Consumer groups dictionary: name -> streamCG */
} stream;
typedef struct streamID {
// 消息创建时的时间
uint64_t ms; /* Unix time in milliseconds. */
// 消息的序号
uint64_t seq; /* Sequence number. */
} streamID;
可以看到 stream 的实现用到了 rax 树
再来看 rax 的实现
typedef struct rax {
// radix tree 的头节点
raxNode *head;
// radix tree 所存储的元素总数,每插入一个 ID,计数加 1
uint64_t numele;
// radix tree 的节点总数
uint64_t numnodes;
} rax;
typedef struct raxNode {
// 表示从 Radix Tree 的根节点到当前节点路径上的字符组成的字符串,是否表示了一个完整的 key
uint32_t iskey:1; /* Does this node contain a key? */
// 表明当前key对应的value是否为空
uint32_t isnull:1; /* Associated value is NULL (don't store it). */
// 表示当前节点是非压缩节点,还是压缩节点。
uint32_t iscompr:1; /* Node is compressed. */
// 压缩节点压缩的字符串长度或者非压缩节点的子节点个数
uint32_t size:29; /* Number of children, or compressed string len. */
// 包含填充字段,同时存储了当前节点包含的字符串以及子节点的指针,key对应的value指针。
unsigned char data[];
} raxNode;
下面的前缀树就是存储了(radix、race、read、real 和 redis)这几个 key 的布局
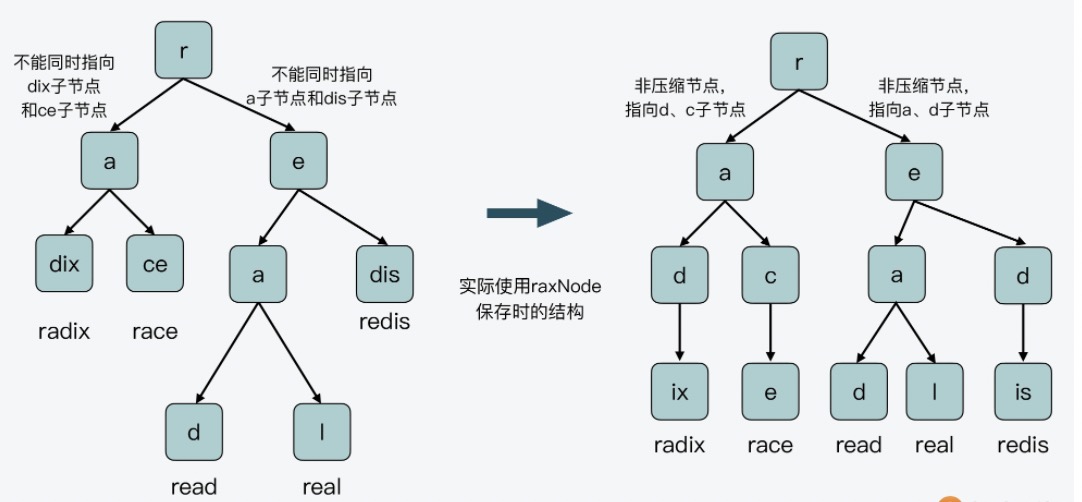
Radix Tree 非叶子节点,要不然是压缩节点,只指向单个子节点,要不然是非压缩节点,指向多个子节点,但每个子节点只表示一个字符。所以,非叶子节点无法同时指向表示单个字符的子节点和表示合并字符串的子节点。
data 是用来保存实际数据的。不过,这里保存的数据会根据当前节点的类型而有所不同:
-
对于非压缩节点来说,data 数组包括子节点对应的字符、指向子节点的指针,以及节点表示 key 时对应的 value 指针;
-
对于压缩节点来说,data 数组包括子节点对应的合并字符串、指向子节点的指针,以及节点为 key 时的 value 指针。
Stream 保存的消息数据,按照 key-value 形式来看的话,消息 ID 就相当于 key,而消息内容相当于是 value。也就是说,Stream 会使用 Radix Tree 来保存消息 ID,然后将消息内容保存在 listpack 中,并作为消息 ID 的 value,用 raxNode 的 value 指针指向对应的 listpack。
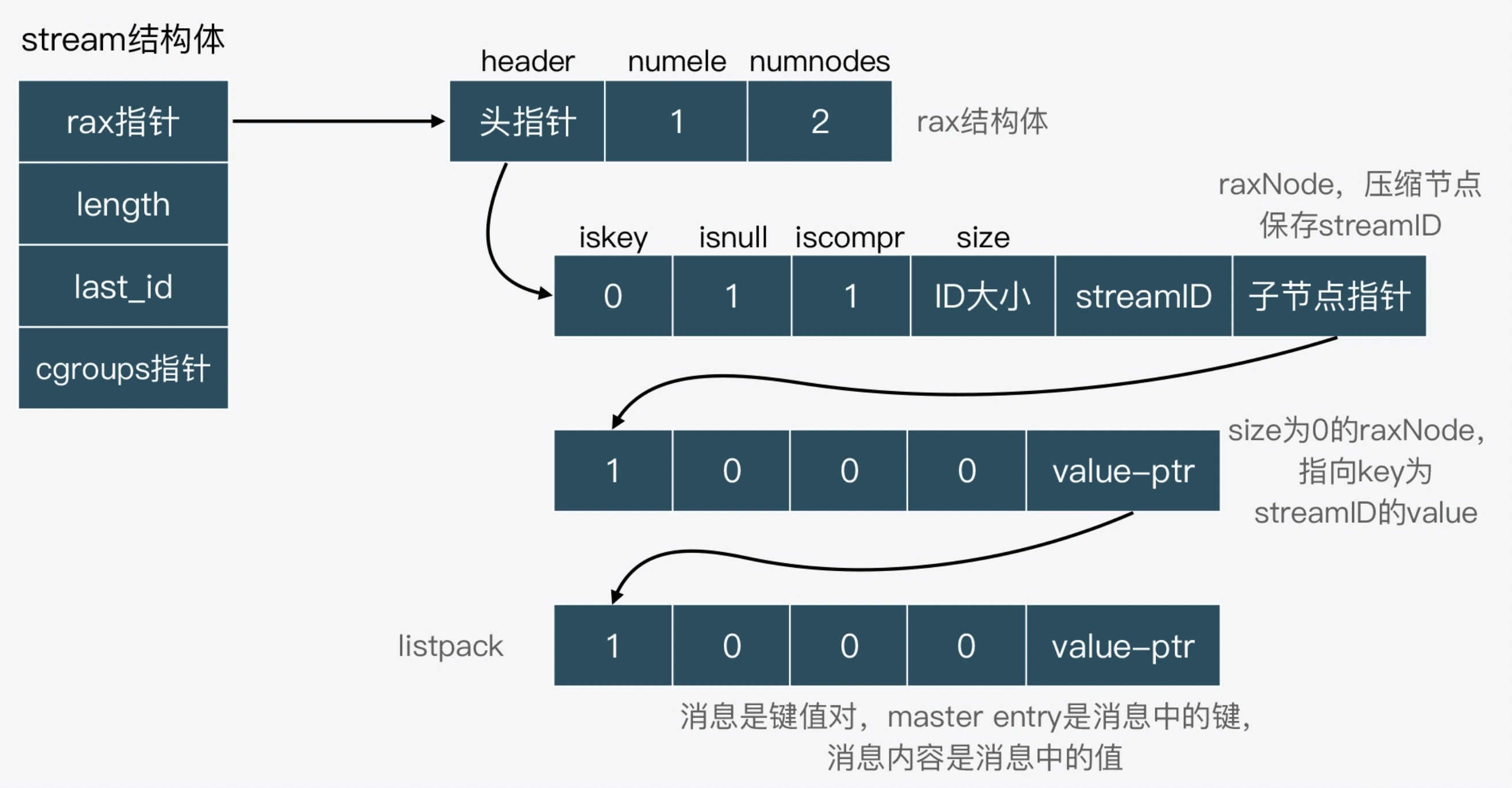
这个 listpack 有点脸盲,listpack 是在 redis5.0 引入了一种新的数据结构,listpack 相比于 ziplist 有哪些优点呢
压缩列表的细节可参见压缩列表
对于压缩列表来讲:保存过大的元素,否则容易导致内存重新分配,甚至可能引发连锁更新的问题。
在 listpack 中,因为每个列表项只记录自己的长度,而不会像 ziplist 中的列表项那样,会记录前一项的长度。所以,当我们在 listpack 中新增或修改元素时,实际上只会涉及每个列表项自己的操作,而不会影响后续列表项的长度变化,这就避免了连锁更新。
streamCG 消费者组
typedef struct streamCG {
// 当前我这个stream的最大id
streamID last_id;
// 还没有收到ACK的消息列表
rax *pel;
// 消费组中的所有消费者,消费者名称为键,streamConsumer 为值
rax *consumers;
} streamCG;
-
last_id: 每个组的消费者共享一个last_id代表这个组消费到了什么位置,每次投递后会更新这个group;
-
pel: 已经发送给客户端,但是还没有收到XACK的消息都存储在pel树里面;
-
consumers: 存储当前这个消费者组中的消费者。
streamConsumer 消费者结构
typedef struct streamConsumer {
// 为该消费者最后一次活跃的时间
mstime_t seen_time;
// 消费者名称,为sds结构
sds name;
// 待ACK的消息列表,和 streamCG 中指向的是同一个
rax *pel;
} streamConsumer;
消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了。
消费者组中会维护 last_id,代表消费者组消费的位置,同时未经 ACK 的消息会存在于 pel 中。
发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
来看下几个主要的命令
PSUBSCRIBE pattern [pattern ...]
订阅一个或多个符合给定模式的频道。
PUBSUB subcommand [argument [argument ...]]
查看订阅与发布系统状态。
PUBLISH channel message
将信息发送到指定的频道。
PUNSUBSCRIBE [pattern [pattern ...]]
退订所有给定模式的频道。
SUBSCRIBE channel [channel ...]
订阅给定的一个或多个频道的信息。
UNSUBSCRIBE [channel [channel ...]]
指退订给定的频道。
普通的订阅
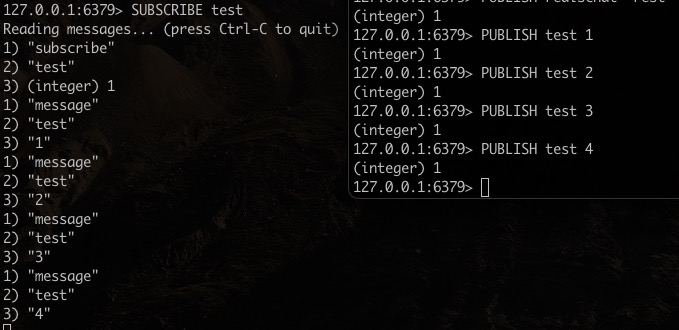
订阅 test
$ SUBSCRIBE test
向 test 发布信息
$ PUBLISH test 1
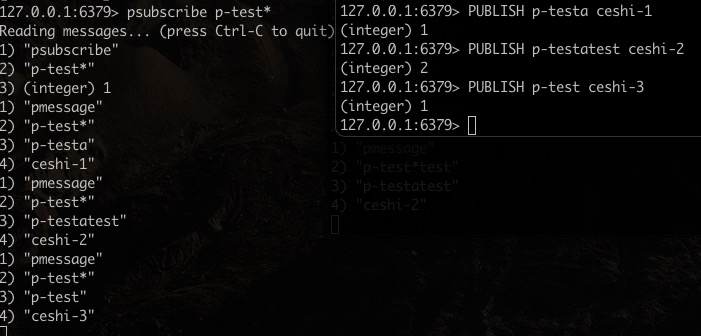
基于模式(pattern)的发布/订阅
相当于是模糊匹配,订阅的时候通过加入通配符中来实现,?表示1个占位符,表示任意个占位符(包括0),?表示1个以上占位符。
订阅
$ psubscribe p-test*
发送信息
$ PUBLISH p-testa ceshi-1
看下源码实现
Redis 将所有频道和模式的订阅关系分别保存在 pubsub_channels 和 pubsub_patterns 中。
代码路径https://github.com/redis/redis/blob/6.0/src/server.h
struct redisServer {
// 保存订阅频道的信息
dict *pubsub_channels; /* Map channels to list of subscribed clients */
// 保存着所有和模式相关的信息
dict *pubsub_patterns; /* A dict of pubsub_patterns */
// ...
}
pubsub_channels 属性是一个字典,字典的键为正在被订阅的频道,而字典的值则是一个链表, 链表中保存了所有订阅这个频道的客户端。
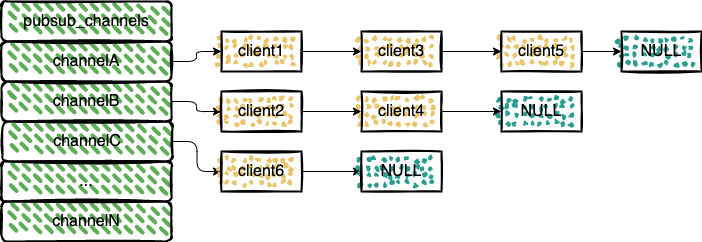
使用 PSUBSCRIBE 命令订阅频道时,就会将订阅的频道和客户端在 pubsub_channels 中进行关联
代码路径 https://github.com/redis/redis/blob/6.2/src/pubsub.c
// 订阅一个频道,成功返回1,已经订阅返回0
int pubsubSubscribeChannel(client *c, robj *channel) {
dictEntry *de;
list *clients = NULL;
int retval = 0;
/* Add the channel to the client -> channels hash table */
// 将频道添加到客户端本地的哈希表中
// 客户端自己也有一个订阅频道的列表,记录了此客户端所订阅的频道
if (dictAdd(c->pubsub_channels,channel,NULL) == DICT_OK) {
retval = 1;
incrRefCount(channel);
// 添加到服务器中的pubsub_channels中
// 判断下这个 channel 是否已经创建了
de = dictFind(server.pubsub_channels,channel);
if (de == NULL) {
// 没有创建,先创建 channel,后添加
clients = listCreate();
dictAdd(server.pubsub_channels,channel,clients);
incrRefCount(channel);
} else {
// 已经创建过了
clients = dictGetVal(de);
}
// 在尾部添加客户端
listAddNodeTail(clients,c);
}
/* Notify the client */
addReplyPubsubSubscribed(c,channel);
}
typedef struct client {
dict *pubsub_channels; /* channels a client is interested in (SUBSCRIBE) */
list *pubsub_patterns; /* patterns a client is interested in (SUBSCRIBE) */
} client;
1、客户端进行订阅的时候,自己本身也会维护一个订阅的 channel 列表;
2、服务端会将订阅的客户端添加到自己的 pubsub_channels 中。
再来看下取消订阅 pubsubUnsubscribeChannel
// 取消 client 订阅
int pubsubUnsubscribeChannel(client *c, robj *channel, int notify) {
dictEntry *de;
list *clients;
listNode *ln;
int retval = 0;
// 客户端在本地的哈希表中删除channel
incrRefCount(channel); /* channel may be just a pointer to the same object
we have in the hash tables. Protect it... */
if (dictDelete(c->pubsub_channels,channel) == DICT_OK) {
retval = 1;
/* Remove the client from the channel -> clients list hash table */
de = dictFind(server.pubsub_channels,channel);
serverAssertWithInfo(c,NULL,de != NULL);
clients = dictGetVal(de);
ln = listSearchKey(clients,c);
serverAssertWithInfo(c,NULL,ln != NULL);
listDelNode(clients,ln);
if (listLength(clients) == 0) {
/* Free the list and associated hash entry at all if this was
* the latest client, so that it will be possible to abuse
* Redis PUBSUB creating millions of channels. */
dictDelete(server.pubsub_channels,channel);
}
}
/* Notify the client */
if (notify) addReplyPubsubUnsubscribed(c,channel);
decrRefCount(channel); /* it is finally safe to release it */
return retval;
}
取消订阅的逻辑也比较简单,先在客户端本地维护的 channel 列表移除对应的 channel 信息,然后在服务端中的 pubsub_channels 移除对应的客户端信息。
再来看下信息是如何进行发布的呢
/* Publish a message */
int pubsubPublishMessage(robj *channel, robj *message) {
int receivers = 0;
dictEntry *de;
dictIterator *di;
listNode *ln;
listIter li;
/* Send to clients listening for that channel */
// 找到Channel所对应的dictEntry
de = dictFind(server.pubsub_channels,channel);
if (de) {
// 获取此 channel 对应的所有客户端
list *list = dictGetVal(de);
listNode *ln;
listIter li;
listRewind(list,&li);
// 一个个发送信息
while ((ln = listNext(&li)) != NULL) {
client *c = ln->value;
addReplyPubsubMessage(c,channel,message);
receivers++;
}
}
/* Send to clients listening to matching channels */
// 拿到所有的客户端信息
di = dictGetIterator(server.pubsub_patterns);
if (di) {
channel = getDecodedObject(channel);
while((de = dictNext(di)) != NULL) {
robj *pattern = dictGetKey(de);
list *clients = dictGetVal(de);
// 这里进行匹配
// 拥有相同的 pattern 的客户端会被放入到同一个链表中
if (!stringmatchlen((char*)pattern->ptr,
sdslen(pattern->ptr),
(char*)channel->ptr,
sdslen(channel->ptr),0)) continue;
listRewind(clients,&li);
while ((ln = listNext(&li)) != NULL) {
client *c = listNodeValue(ln);
addReplyPubsubPatMessage(c,pattern,channel,message);
receivers++;
}
}
decrRefCount(channel);
dictReleaseIterator(di);
}
return receivers;
}
消息的发布,除了会向 pubsub_channels 中的客户端发送信息,也会通过 pubsub_patterns 给匹配的客户端发送信息。
通过 channel 订阅,通过 channel 找到匹配的客户端链表,然后逐一发送
通过 pattern 订阅,拿出所有的 patterns ,然后根据规则,对 发送的 channel ,进行一一匹配,找到满足条件的客户端然后发送信息。
再来看下 pubsub_patterns 中的客户端数据是如何保存的
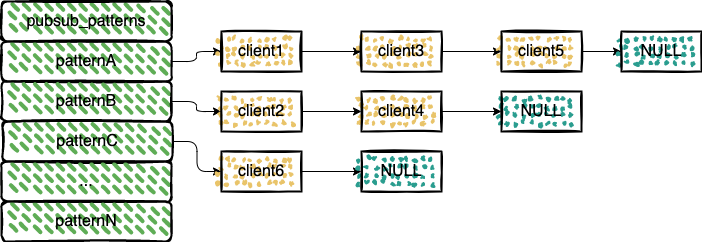
/* Subscribe a client to a pattern. Returns 1 if the operation succeeded, or 0 if the client was already subscribed to that pattern. */
int pubsubSubscribePattern(client *c, robj *pattern) {
dictEntry *de;
list *clients;
int retval = 0;
// 如果客户端没有订阅过
if (listSearchKey(c->pubsub_patterns,pattern) == NULL) {
retval = 1;
// 客户端端本地进行记录
listAddNodeTail(c->pubsub_patterns,pattern);
incrRefCount(pattern);
/* Add the client to the pattern -> list of clients hash table */
de = dictFind(server.pubsub_patterns,pattern);
if (de == NULL) {
// 没有创建,先创建
clients = listCreate();
dictAdd(server.pubsub_patterns,pattern,clients);
incrRefCount(pattern);
} else {
clients = dictGetVal(de);
}
listAddNodeTail(clients,c);
}
/* Notify the client */
addReplyPubsubPatSubscribed(c,pattern);
return retval;
}
这里订阅 pattern 的流程和订阅 channel 的流程有点类似,只是这里存储的是 pattern。pubsub_patterns 的类型也是 dict。
拥有相同的 pattern 的客户端会被放入到同一个链表中。看 redis 的提交记录可以发现,原本 pubsub_patterns 的类型是 list,后面调整成了 dict。issues
This commit introduced a dictionary on the server side to efficiently handle the pub sub pattern matching. However, there is another list maintaining the same information which is redundant as well as expensive to operate on. Hence removing it.
如果是一个链表,就需要遍历所有的链表,使用 dict ,将有相同 pattern 的客户端放入同一个链表中,这样匹配前面的 pattern 就好了,不用遍历所有的客户端节点。
总结
redis 中消息队列的实现,可以使用 list,Streams,pub/sub。
1、list 不支持消费者组;
2、发布订阅 (pub/sub) 消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃,分发消息,无法记住历史消息;
3、5.0 引入了 Streams,专门为消息队列设计的数据结构,其中支持了消费者组,支持消息的有序性,支持消息的持久化;
参考
【Redis核心技术与实战】https://time.geekbang.org/column/intro/100056701
【Redis设计与实现】https://book.douban.com/subject/25900156/
【Redis Streams 介绍】http://www.redis.cn/topics/streams-intro.html
【Centos7.6安装redis-6.0.8版本】https://blog.csdn.net/roc_wl/article/details/108662719
【Stream 数据类型源码分析】https://blog.csdn.net/weixin_45505313/article/details/109060761
【订阅与发布】https://redisbook.readthedocs.io/en/latest/feature/pubsub.html
【Redis学习笔记】https://github.com/boilingfrog/Go-POINT/tree/master/redis