k8s 中的网络模型
CNI 网络插件
docker 容器的网络都是连接在 docker0 网桥上的,容器中所有的流量都由 docker0 网桥转发出去。
例如 Flannel 中 UDP 模式通过 TUN 设备,VXLAN 模式通过 VTEP 设备,来接入容器中的网络,这些设备都是连接在 docker0 网桥上面和容器中的网络进行交互的。
网络插件的作用就是把这些宿主机中的网络设备连通,从而达到网络跨主机通信的目的。
Kubernetes 中处理网络的方式和容器中的类似,不是的是 Kubernetes 中使用 CNI 网桥,替代了 docker0 网桥。
例如 Flannel 的 VXLAN 模式,在 Kubernetes 中和 docker 容器中的工作方式基本相同,只是 docker0 网桥被替换成了 CNI 网桥。
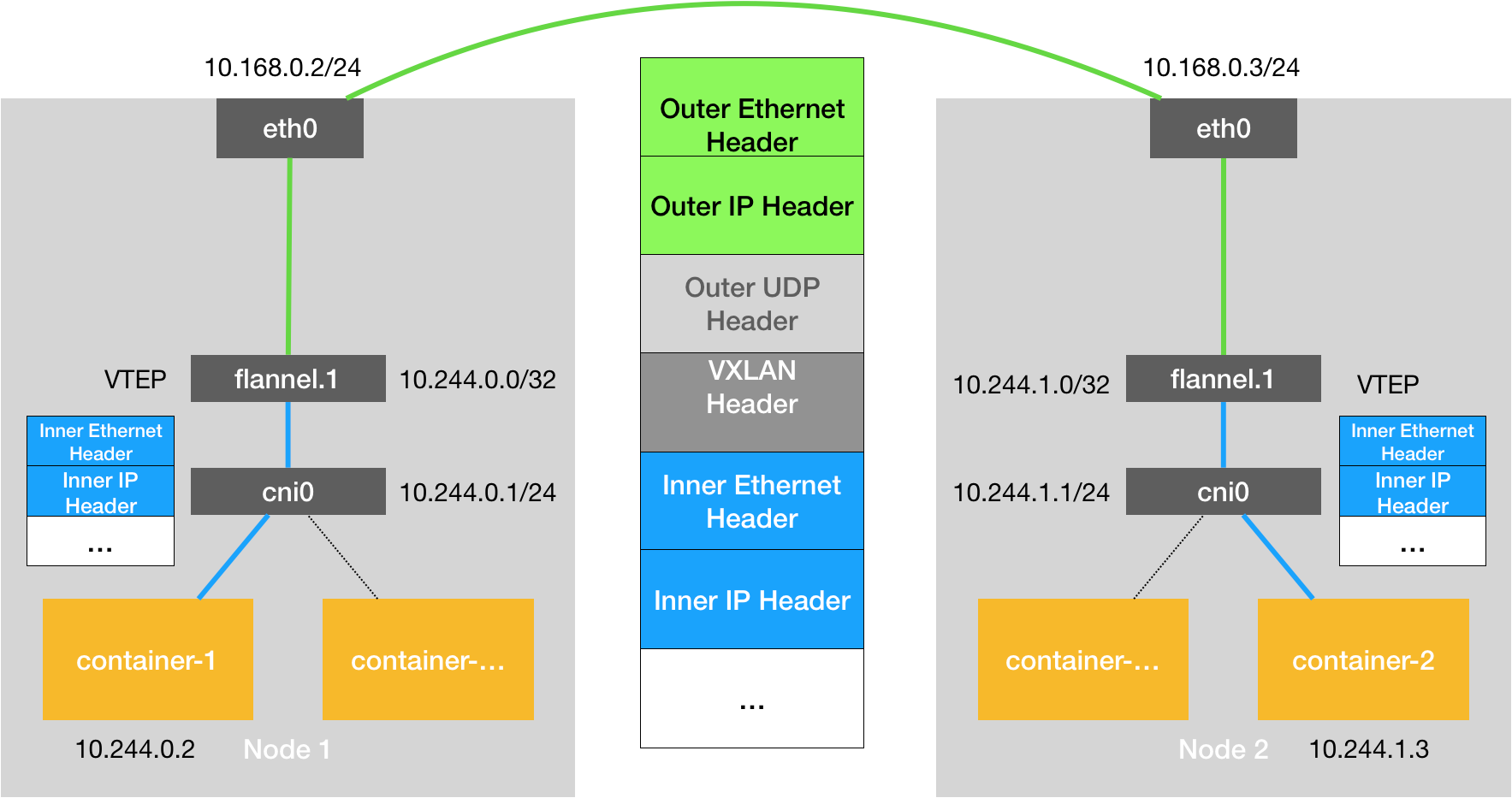
CNI 的设计思想
CNI 的设计思想:Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络插件,为这个 Infra 容器的 Network Namespace,配置符合预期的网络栈。
CNI 的基础可执行文件有下面三类:
1、Main 插件,用来创建具体网络设备的二进制文件,栗如 bridge(网桥设备)、ipvlan、loopback(lo 设备)等;
2、IPAM 插件,负责分配 IP 地址的二进制文件,栗如 dhcp,这个文件会向 DHCP 服务器发起请求;host-local,则会使用预先配置的 IP 地址段来进行分配;
3、是由 CNI 社区维护的内置 CNI 插件。
要实现一个 Kubernetes 中的网络有下面两个步骤
1、实现网络方案本身。栗如:对于 Flannel ,就是要实现 flanneld 进程里的主要逻辑。创建和配置 flannel.1 设备、配置宿主机路由、配置 ARP 和 FDB 表里的信息等等;
2、实现该网络方案对应的 CNI 插件。要做的就是配置 Infra 容器里面的网络栈,并把它连接在 CNI 网桥上。
k8s 中的三层网络
这里通过 Flannel 的 host-gw 模式和 Calico 项目来了解下 k8s 中的三层网络。
Flannel 的 host-gw
host-gw 即 Host Gateway,这个模式就是将每个 Flannel 子网的下一跳,设置成了该子网对应的宿主机的 IP 地址。这样宿主机就充当了容器通信路径的”网关”作用。
Flannel 子网和主机的信息,都被保存在 etcd 中,flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。
注意:在 Kubernetes v1.7 之后,类似 Flannel、Calico 的 CNI 网络插件都是可以直接连接 Kubernetes 的 APIServer 来访问 Etcd 的,无需额外部署 Etcd 给它们使用。

host-gw 模式,容器的通行过程,没有了额外的解包和封包的带来的性能损耗,对比 VXLAN 模式有更高的性能。
host-gw 模式能够工作的核心就是在于 IP 包被封装成帧发出去的时候,会使用路由表中的”下一跳”来设置目的 MAC 地址,这样就能通过二层网络到达目的宿主机。
Calico
Calico 项目提供的网络解决方案与 Flannel 的 host-gw 模式,几乎是完全一样的。
不同点:
1、Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,Calico 项目使用了 BGP 来自动地在整个集群中分发路由信息;
BGP 的全称是 Border Gateway Protocol,即:边界网关协议。它是一个 Linux 内核原生就支持的、专门用在大规模数据中心里维护不同的“自治系统”之间路由信息的、无中心的路由协议。
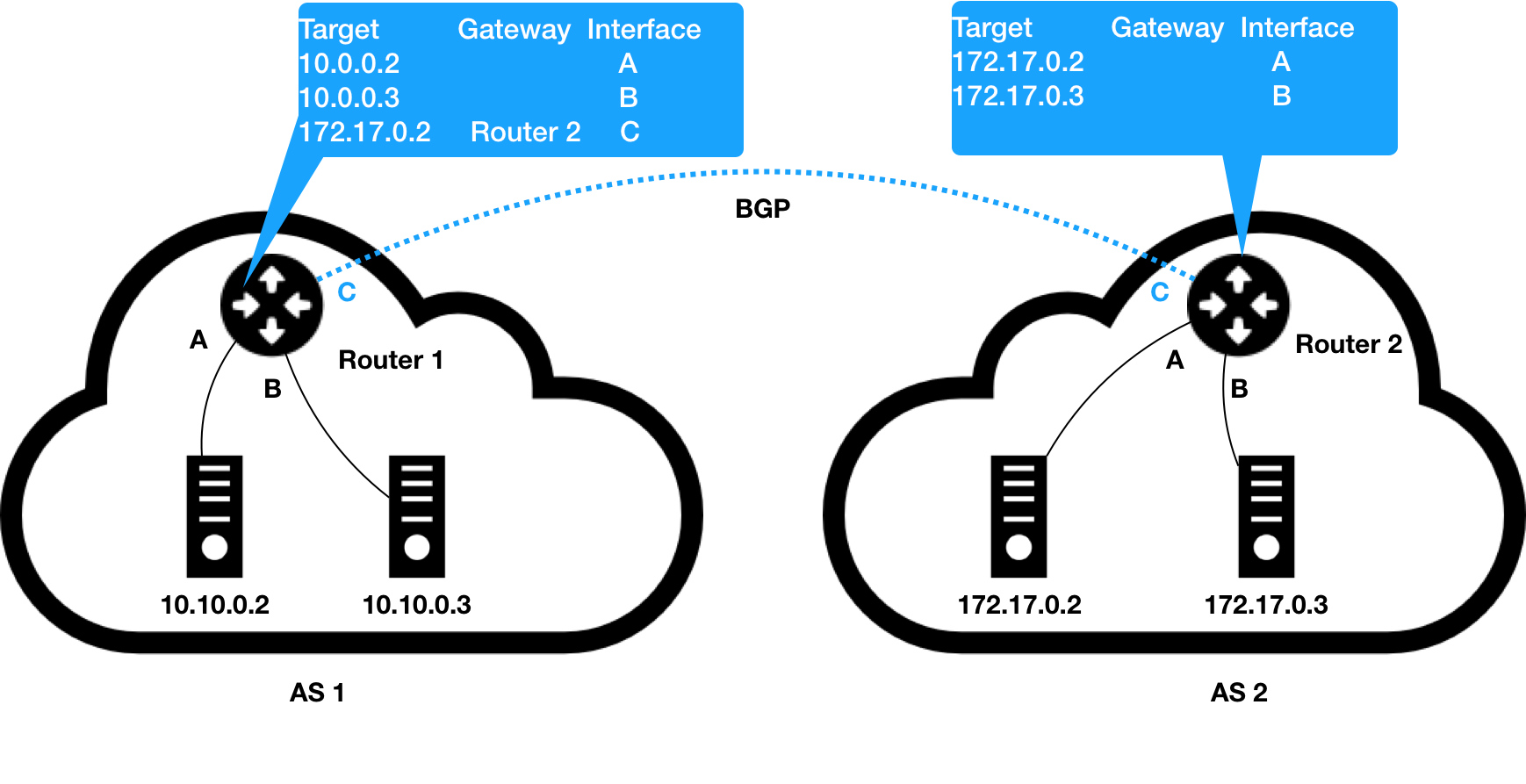
自制系统,指的是一个组织管辖下的所有 IP 网络和路由器的全体。正常情况下,这些自制系统之间是不能进行通信的。
在互联网中,一个自治系统(AS)是一个有权自主地决定在本系统中应采用各种路由协议的小型单位。这个网络单位可以是一个简单的网络也可以是一个由一个或多个普通的网络管理员来控制的网络群体,它是一个单独的可管理的网络单元(例如一所大学,一个企业或者一个公司个体)。一个自治系统有时也被称为是一个路由选择域(routing domain)。一个自治系统将会分配一个全局的唯一的16位号码,有时我们把这个号码叫做自治系统号(ASN)。
如果两个自制系统的主机需要进行 IP 通信,就需要使用路由器,把这两个自制系统连接起来。
我们把连接自制系统的路由器称为边界网关,和普通路由器之间的区别就是,它的路由表里拥有其他自治系统里的主机路由信息。
如果有网络拓扑很复杂,手动连接各个自制系统肯定是不现实的,BGP 正是用来解决这个问题的。
2、Calico 项目与 Flannel 的 host-gw 模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备。
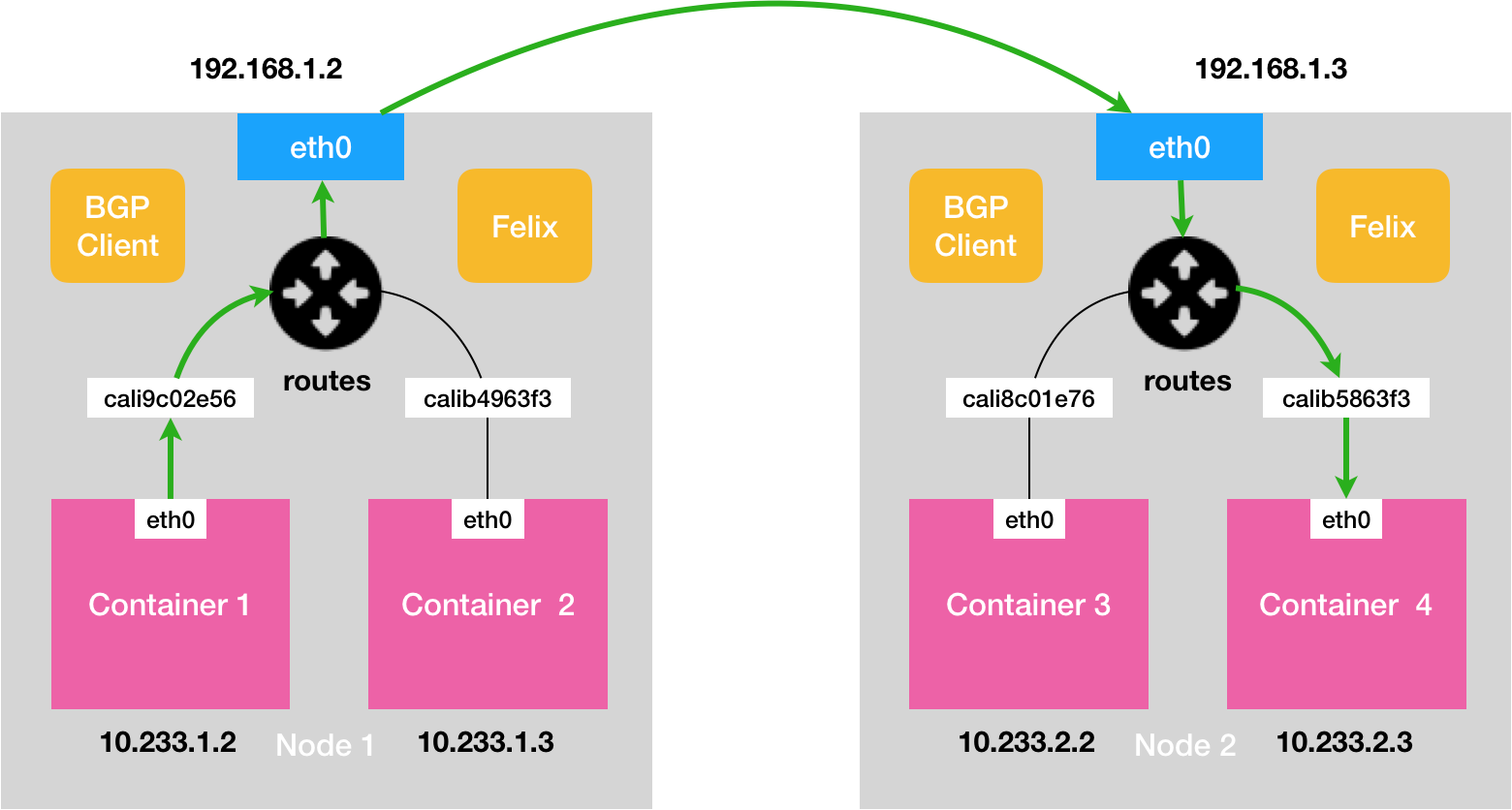
容器发出的 IP 包会直接经过 Veth Pair 设备出现在宿主机上,宿主机会根据规则的下一跳 IP ,将 IP 包转发给正确的网关。
最核心的下一跳的规则路由,由 Calico 的 Felix 进程负责维护。Calico 项目将集群中的所有节点都当成边界路由来处理了,共同组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。这些节点,称之为为 BGP Peer。
Calico 网络使用的默认配置是 Node-to-Node Mesh 模式,每台宿主机上的 BGP Client 都需要跟其他所有节点的 BGP Client 进行通信以便交换路由信息。但是,随着节点数量 N 的增加,这些连接的数量就会以 N² 的规模快速增长,从而给集群本身的网络带来巨大的压力。该模式一般推荐用在少于 100 个节点的集群里。
如果有更大的集群就推荐使用 Route Reflector 的模式,这种模式下,Calico 会指定一个或几个专门的节点,来负责和所有的节点建立 BGP 连接从而学习到全局的路由规则。其他的节点只需要和这几个节点进行路由交换,就能获得整个集群的路由规则了。通过这些中间代理节点从而将 BGP 连接的规模控制在 N 的数量级上。
如果对应的两个 Node 不在同一个子网内,就没有办法通过二层网络把 IP 包发送到下一跳的地址。这种情况下,就需要为 Calico 打开 IPIP 模式 。
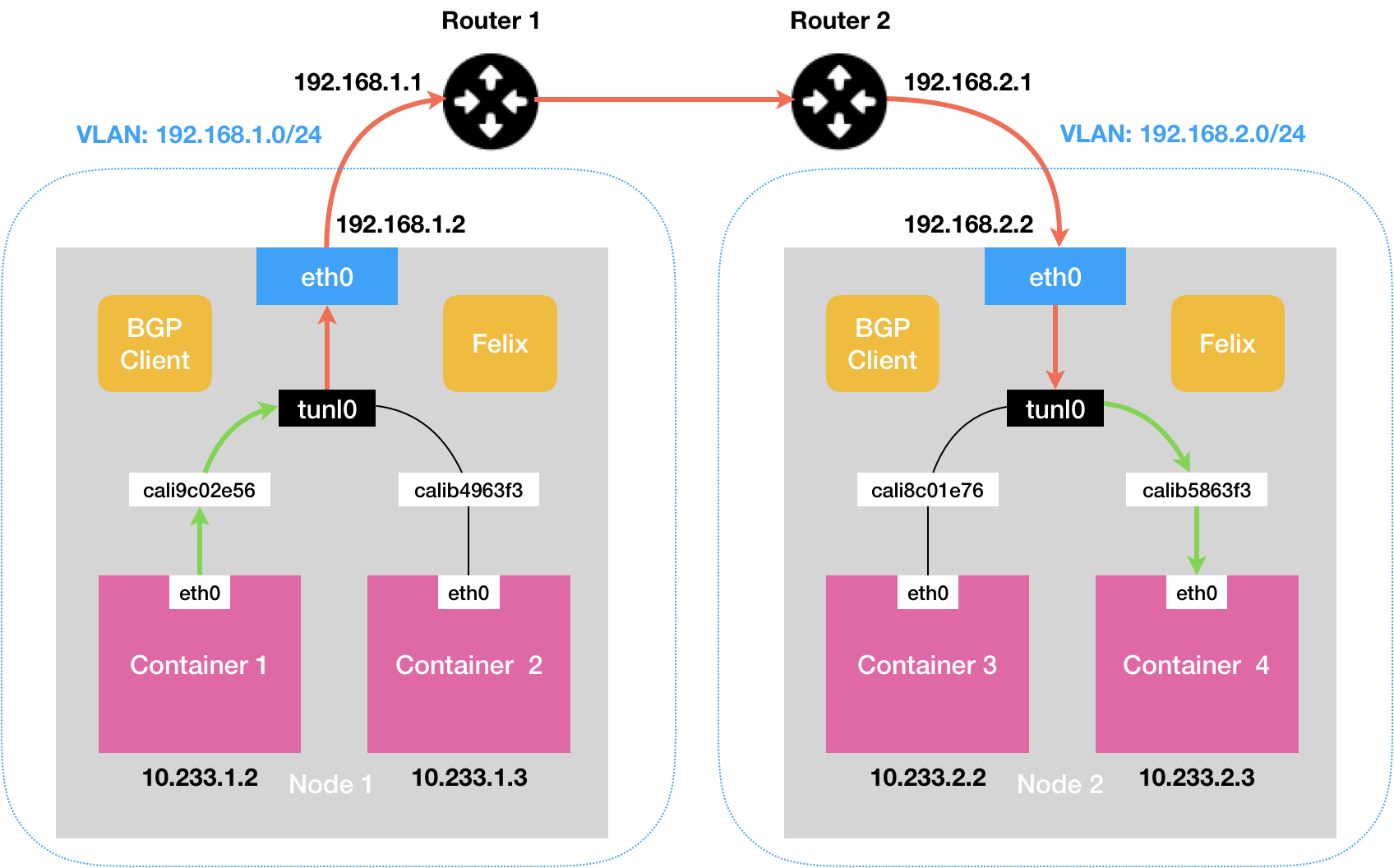
Calico IPIP 模式中使用了 tunl0 ,一个 IP 隧道(IP tunnel)设备。
IP 包进入 IP 隧道设备之后,就会被 Linux 内核的 IPIP 驱动接管。IPIP 驱动会将这个 IP 包直接封装在一个宿主机网络的 IP 包中。
这样,原先从容器到 Node 2 的 IP 包,就被伪装成了一个从 Node 1 到 Node 2 的 IP 包。
由于宿主机之间已经使用路由器配置了三层转发,也就是设置了宿主机之间的“下一跳”。所以这个 IP 包在离开 Node 1 之后,就可以经过路由器,最终“跳”到 Node 2 上。
这时,Node 2 的网络内核栈会使用 IPIP 驱动进行解包,从而拿到原始的 IP 包。然后,原始 IP 包就会经过路由规则和 Veth Pair 设备到达目的容器内部。
参考
【深入剖析 Kubernetes】https://time.geekbang.org/column/intro/100015201?code=UhApqgxa4VLIA591OKMTemuH1%2FWyLNNiHZ2CRYYdZzY%3D