go中string是如何实现的呢
前言
go中的string可谓是用到的最频繁的关键词之一了,如何实现,我们来探究下
实现
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
string我们看起来是一个整体,但是本质上是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组,相比于切片仅仅少了一个Cap属性。
src/reflect/value.go
type StringHeader struct {
Data uintptr
Len int
}
切片的数据结构
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
1、相比于切片少了一个容量的cap字段,就意味着string是不能发生地址空间扩容;
2、可以把string当成一个只读的切片类型;
3、string本身的切片是只读的,所以不会直接向字符串直接追加元素改变其本身的内存空间,所有在字符串上的写入操作都是通过拷贝实现的。
go语言中的string是不可变的
func main() {
s := "212"
fmt.Println(&s)
fmt.Println(len(s))
s = "33hhhhhhhhhnihihfnHSIHISASIASJAISJAISJAISJAISJAISA"
fmt.Println(&s)
fmt.Println(len(s))
}
上面的例子,s发生了,两次赋值,里面的值发生了改变,好奇怪,明明是不可修改的
go中的字符串底层也是引用类型,类似切片,只是对比切片少了一个cap字段,也就是不能发生扩容。也包含一个指针,指向它引用的字节系列的数组[]byte,所以当改变一个字符串的值,原来指针指向的[]byte将被丢弃,字符串包含的指针,将指向一个新的值转换而来的字节数组。所以说字符串的值是不能被修改的,对于重新赋值,老的值没有被修改,只是被弃用了。
[]byte转string
src/runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
// 判断传入的缓冲区大小,决定是否重新分配内存
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
// 重新分配内存
p = mallocgc(uintptr(len(b)), nil, false)
}
// 将输出的str转化成stringStruct结构
// 并且赋值
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
// 将[]byte中的内容,复制到内存空间p中
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
// 转换成
func stringStructOf(sp *string) *stringStruct {
return (*stringStruct)(unsafe.Pointer(sp))
}
总结下流程:
1、根据传入的内存大小,判断是否需要分配重新分配内存;
2、构建stringStruct,分类长度和内存空间;
3、赋值[]byte里面的数据到新构建stringStruct的内存空间中。
string转[]byte
src/runtime/string.go
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
// 为[]byte重新分配一段内存
func rawbyteslice(size int) (b []byte) {
cap := roundupsize(uintptr(size))
p := mallocgc(cap, nil, false)
if cap != uintptr(size) {
memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))
}
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}
return
}
1、判断传入的缓存区大小,如果内存够用就使用传入的缓冲区存储 []byte;
2、传入的缓存区的大小不够,调用 runtime.rawbyteslice创建指定大小的[]byte;
3、将string拷贝到切片。
字符串的拼接
+方式进行拼接
func main() {
s := "hai~"
s += "hello world"
fmt.Println(s)
}
一个拼接语句的字符串编译时都会被存放到一个切片中,拼接过程需要遍历两次切片,第一次遍历获取总的字符串长度,据此申请内存,第二次遍历会把字符串逐个拷贝过去。
所以,这种方式拼接只要性能问题是在copy上,适合短小的、常量字符串(明确的,非变量)。
fmt 拼接
func main() {
s := fmt.Sprintf("%s%s%d", "hello", "world", 2021)
fmt.Println(s)
}
fmt可以方便对各种类型的数据进行拼接,转换成string,具体详见printf的用法
Join 拼接
func main() {
var s []string
s = append(s, "hello")
s = append(s, "world")
fmt.Println(strings.Join(s, ""))
}
buffer 拼接
func main() {
var b bytes.Buffer
b.WriteString("hello")
b.WriteString("world")
fmt.Println(b.String())
}
builder 拼接
func main() {
var b bytes.Buffer
b.WriteString("hello")
b.WriteString("world")
fmt.Println(b.String())
}
测试下几种方法的性能
压力测试
package main
import (
"bytes"
"fmt"
"strings"
"testing"
)
func String() string {
var s string
s += "hello" + "\n"
s += "world" + "\n"
s += "今天的天气很不错的"
return s
}
func BenchmarkString(b *testing.B) {
for i := 0; i < b.N; i++ {
String()
}
}
func StringFmt() string {
return fmt.Sprintf("%s %s %s", "hello", "world", "今天的天气很不错的")
}
func BenchmarkStringFmt(b *testing.B) {
for i := 0; i < b.N; i++ {
StringFmt()
}
}
func StringJoin() string {
var s []string
s = append(s, "hello ")
s = append(s, "world ")
s = append(s, "今天的天气很不错的 ")
return strings.Join(s, "")
}
func BenchmarkStringJoin(b *testing.B) {
for i := 0; i < b.N; i++ {
StringJoin()
}
}
func StringBuffer() string {
var s bytes.Buffer
s.WriteString("hello ")
s.WriteString("world ")
s.WriteString("今天的天气很不错的 ")
return s.String()
}
func BenchmarkStringBuffer(b *testing.B) {
for i := 0; i < b.N; i++ {
StringBuffer()
}
}
func StringBuilder() string {
var s strings.Builder
s.WriteString("hello ")
s.WriteString("world ")
s.WriteString("今天的天气很不错的 ")
return s.String()
}
func BenchmarkStringBuilder(b *testing.B) {
for i := 0; i < b.N; i++ {
StringBuilder()
}
}
看下执行的结果
$ go test string_test.go -bench=. -benchmem -benchtime=3s
goos: darwin
goarch: amd64
BenchmarkString-4 28862838 115 ns/op 64 B/op 2 allocs/op
BenchmarkStringFmt-4 20697505 169 ns/op 48 B/op 1 allocs/op
BenchmarkStringJoin-4 11304583 293 ns/op 160 B/op 4 allocs/op
BenchmarkStringBuffer-4 31151836 104 ns/op 112 B/op 2 allocs/op
BenchmarkStringBuilder-4 29142151 120 ns/op 72 B/op 3 allocs/op
PASS
ok command-line-arguments 17.740s
ns/op 平均一次执行的时间
B/op 平均一次真申请的内存大小
allocs/op 平均一次,申请的内存次数
从上面我们就能直观的看出差距,不过差距不大,当然具体的性能信息要结合当前go版本,具体讨论。
看上去很low的+拼接方式,在性能上倒是还不错。
go101中评论
标准编译器对使用+运算符的字符串衔接做了特别的优化。 所以,一般说来,在被衔接的字符串的数量是已知的情况下,使用+运算符进行字符串衔接是比较高效的。
我的版本是go version go1.13.15 darwin/amd64
字符类型
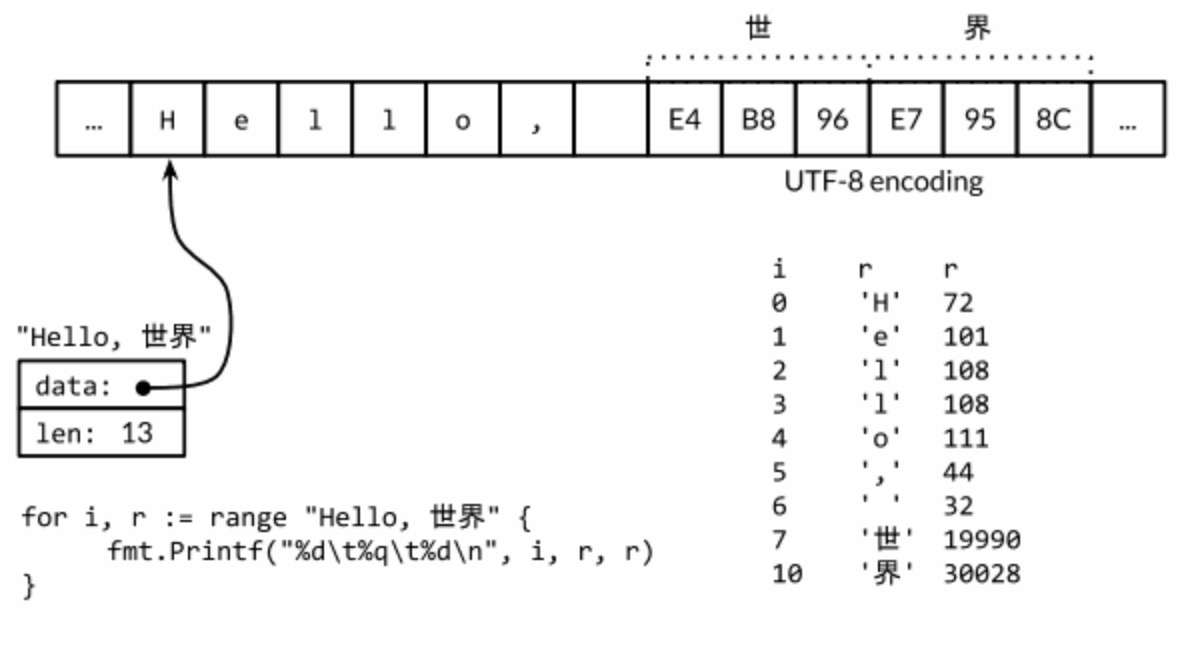
我们在go中经常遇到rune和byte两种字符串类型,作为go中字符串的两种类型:
byte
byte 也叫 uint8。代表了 ASCII 码的一个字符。
对于英文,一个ASCII表示一个字符,根据ASCII表。我们知道
A对应的十进制编码是65。我们看看byte打印的结果
func main() {
s := "A"
fmt.Print("打印下[]byte(s),结果十进制:")
fmt.Println([]byte(s))
fmt.Print("打印下[]byte(s)中存储的类型,存储的是十六进制:")
fmt.Printf("%#v\n", []byte(s))
s1 := "世界"
fmt.Print("打印下[]byte(s1),结果十进制:")
fmt.Println([]byte(s1))
fmt.Print("打印下[]byte(s1)中存储的类型,存储的是十六进制:")
fmt.Printf("%#v\n", []byte(s1))
fmt.Print("打印下s1的十六进制:")
fmt.Printf("%x\n", s1)
}
结果
打印下[]byte(s),结果十进制:[65]
打印下[]byte(s)中存储的类型,存储的是十六进制:[]byte{0x41}
打印下[]byte(s1),结果十进制:[228 184 150 231 149 140]
打印下[]byte(s1)中存储的类型,存储的是十六进制:[]byte{0xe4, 0xb8, 0x96, 0xe7, 0x95, 0x8c}
打印下s1的十六进制:e4b896e7958c
对于ASCII一个索引位表示一个字符(也就是英文)
对于非ASCII,索引更新的步长将超过1个字节,中文的是三个字节表示一个中文。
rune
rune 等价于 int32 类型,UTF8编码的Unicode码点。
func main() {
s := "哈哈"
fmt.Println([]rune(s))
s1 := "A"
fmt.Println([]rune(s1))
}
打印下结果
[21704 21704]
[65]
我们可以看到里面对应的是UTF-8的十进制数字。对于英文来讲UTF-8的码点,就是对应的ASCII。
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
关于Unicode和UTF8的区别和联系,以及ASCII码的联系,参考字符编码-字库表,字符集,字符编码
内存泄露的场景
不正确的使用会导致短暂的内存泄露
var s0 string // 一个包级变量
func main() {
s := bigString() // 申请一个大string
// 如果f函数的执行链路很长,申请的大s的内存将得不到释放,直到f函数执行完成被gc
f(s)
}
func f(s1 string) {
s0 = s1[:50]
// 目前,s0和s1共享着承载它们的字节序列的同一个内存块。
// 虽然s1到这里已经不再被使用了,但是s0仍然在使用中,
// 所以它们共享的内存块将不会被回收。虽然此内存块中
// 只有50字节被真正使用,而其它字节却无法再被使用。
}
func bigString() string {
var buf []byte
for i := 0; i < 10; i++ {
buf = append(buf, make([]byte, 1024*1024)...)
}
return string(buf)
}
上面的例子,一个大的变量s1,另一个字符串s0对这个变量进行了部分引用,新申请的变量s0和老的变量s1共用同一块内存。所以虽然大变量s1不用了,但是也不能马上被gc。
解决方法
思路是发生一次copy,类似go中闭包的解决方法
strings.Builder
func f(s1 string) {
var b strings.Builder
b.Grow(50)
b.WriteString(s1[:50])
s0 = b.String()
}
感觉有点繁琐,当前也可以使用strings.Repeat, 从Go 1.12开始,此函数也是用strings.Builder实现的。
func Repeat(s string, count int) string {
if count == 0 {
return ""
}
if count < 0 {
panic("strings: negative Repeat count")
} else if len(s)*count/count != len(s) {
panic("strings: Repeat count causes overflow")
}
n := len(s) * count
var b Builder
b.Grow(n)
b.WriteString(s)
for b.Len() < n {
if b.Len() <= n/2 {
b.WriteString(b.String())
} else {
b.WriteString(b.String()[:n-b.Len()])
break
}
}
return b.String()
}
使用demo
func main() {
res := strings.Repeat("你好", 1)
fmt.Println(res)
}
string和[]byte如何取舍
- string 擅长的场景:
需要字符串比较的场景;
不需要nil字符串的场景;
- []byte擅长的场景:
修改字符串的场景,尤其是修改粒度为1个字节;
函数返回值,需要用nil表示含义的场景;
需要切片操作的场景;
所以底层实现会发现有很多[]byte
总结
1、字符串不允许修改,string不包含内存空间,只有一个内存的指针,这样做的好处是string变得非常轻量,可以很方便的进行传递而不用担心内存拷贝;
2、我们阅读go源码,会发现很多地方使用[]byte,使用[]byte能更方便的修改字符串;
3、go中的[]byte存储的是十六进制的ascii码,对于英文一个ascii码表示一个字母,对于中文是三个ascii码表示一个字母;
4、对于[]rune来讲,里面存储的是UTF8编码的Unicode码点,关于UTF8和Unicode区别,Unicode是字符集,UTF8是字符集编码,是Unicode规则字库的一种实现形式;
5、字符串的不正确使用会发生内存泄露;
6、对于字符串的拼接,+拼接是一种看上去low,但是对于短小的、常量字符串(明确的,非变量),效率还不错的方法;
参考
【字符串】https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-string/
【字符串】https://chai2010.gitbooks.io/advanced-go-programming-book/content/ch1-basic/ch1-03-array-string-and-slice.html
【Golang中的string实现】https://erenming.com/2019/12/11/string-in-golang/
【字符串】https://gfw.go101.org/article/string.html
【Go string 实现原理剖析(你真的了解string吗)】https://my.oschina.net/renhc/blog/3019849
【Go语言字符串高效拼接(一)】https://cloud.tencent.com/developer/article/1367934
【Go语言字符类型(byte和rune)】http://c.biancheng.net/view/18.html
【go 的 [] rune 和 [] byte 区别】https://learnku.com/articles/23411/the-difference-between-rune-and-byte-of-go
【go语言圣经】http://books.studygolang.com/gopl-zh/ch3/ch3-05.html
【【Go语言踩坑系列(二)】字符串】https://www.mdeditor.tw/pl/pCg8
【为什么说go语言中的string是不可变的?】https://studygolang.com/topics/3727